400-123-4321
400-123-4321
做图像识别有很多不同的途径。谷歌最近发布了一个使用Tensorflow的物体识别API,让计算机视觉在各方面都更进了一步。
这篇文章将带你测试这个新的API,并且把它应用在youtube上(可以在GitHub上获取用到的全部代码,链接),结果如下:
这个API是用COCO(文本中的常见物体)数据集(http://mscoco.org/)训练出来的。这是一个大约有30万张图像、90种最常见物体的数据集。物体的样本包括:
这个API提供了5种不同的模型,使用者可以通过设置不同检测边界范围来平衡运行速度和准确率。

(想要了解更多跟模型有关的知识:链接)
我决定使用最轻量级的模型(ssd_mobilenet)。主要步骤如下:
1. 下载一个打包模型(.pb-protobuf)并把它载入缓存
2. 使用内置的辅助代码来载入标签,类别,可视化工具等等。
3. 建立一个新的会话,在图片上运行模型。
总体来说步骤非常简单。而且这个API文档还提供了一些能运行这些主要步骤的Jupyter文档——链接
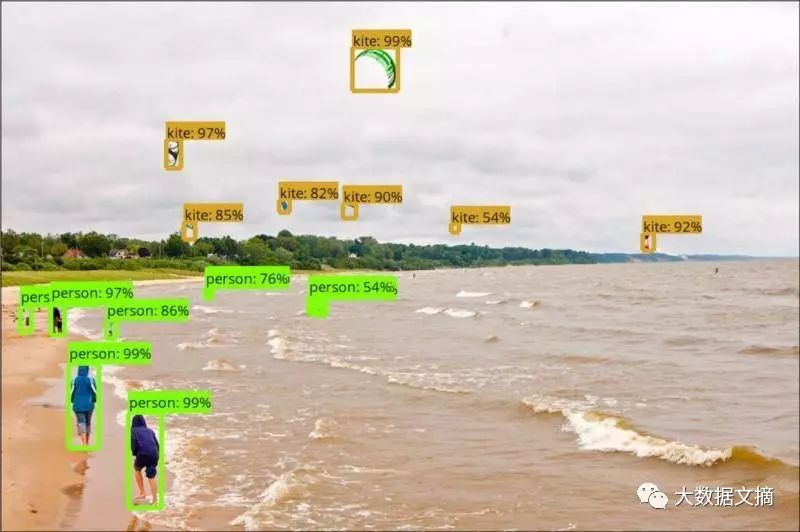
这个模型在实例图像上表现得相当出色(如下图):
接下来我打算在视频上尝试这个API。我使用了Python moviepy库,主要步骤如下:
首先,使用VideoFileClip函数从视频中提取图像;
然后使用fl_image函数在视频中提取图像,并在上面应用物体识别API。fl_image是一个很有用的函数,可以提取图像并把它替换为修改后的图像。通过这个函数就可以实现在每个视频上提取图像并应用物体识别;
最后,把所有处理过的图像片段合并成一个新视频。
对于3-4秒的片段,这个程序需要花费大概1分钟的时间来运行。但鉴于我们使用的是一个载入缓存的模型,而且没有使用GPU,我们实现的效果还是很惊艳的!很难相信只用这么一点代码,就可以以很高的准确率检测并且在很多常见物体上画出边界框。
当然,我们还是能看到有一些表现有待提升。比如下面的例子。这个视频里的鸟完全没有被检测出来。
再进一步,继续探索
几个进一步探索这个API的想法:
尝试一些准确率更高但成本也更高的模型,看看他们有什么不同;
寻找加速这个API的方法,这样它就可以被用于车载装置上进行实时物体检测;
谷歌也提供了一些技能来应用这些模型进行传递学习。例如,载入打包模型后添加一个带有不同图像类别的输出层。
转载36氪:http://36kr.com/p/5090812.html